Proseminar Intelligente Benutzerschnittstellen
Prof. Wahlster
Universität des Saarlandes
Wintersemester 1998 / 99
User-Centered Modeling for Spoken Language and Multimodal Interfaces
(Benutzerorientierte Modelle für Sprach- und Multimodal-Schnittstellen)
Vortrag von Ronald Bieber, schriftliche Ausarbeitung und Handout
Einführung
„Durch Modellierung schwieriger Quellen linguistischer Variabilität in Dialogen und Sprache können wir Schnittstellen entwickeln, die menschliche Eingaben transparent lenken um sie den Verarbeitungsfähigkeiten eines Systems anzupassen.
Arbeit dieser Art wird robustere und stärker Benutzer-orientierte Schnittstellen für sprach- und multimodal-gesteuerte Systeme der nächsten Generation liefern.“
Für denjenigen, der sich mit den hier behandelten Themen nicht näher auseinandergesetzt hat, stellen die beiden obigen Paragraphen alles andere als eine leichte Einführung dar. Daher sollen hier zunächst einige Erläuterungen folgen.
„Modellierung schwieriger Quellen linguistischer Variabilität in Dialogen und Sprache (speech and language)“ heißt nichts anderes, als das untersucht werden soll, warum Menschen in genau derselben Situation leicht unterschiedliche Dinge sagen, und sei es nur durch ein eingefügtes „Ähh..“.
„Schnittstellen entwickeln [...] Eingaben transparent lenken [...] den Verarbeitungsfähigkeiten eines Systems anpassen“: Wir wollen Systeme so entwickeln, dass die zu erwartende Eingabe die Fähigkeiten des Systems nicht überlastet.
Alles, was der zweite Paragraph hierzu noch ergänzt, ist, dass das Ziel dieser Forschung (kommerziell verwertbare) Systeme mit verschiedenen Eingabemöglichkeiten sein sollen.
Soviel zur Einleitung.
Diesem Vortrag liegt der Artikel
User-Centered Modeling for Spoken Language and Multimodal Interfaces
von  Sharon Oviatt
Sharon Oviatt
vom Oregon Graduate Institute of Science & Technology
in Portland, Oregon, USA
zugrunde.
Forschungsgebiet der Arbeit: Sprachtechnologie und Benutzerschnittstellen
Die (leider) verbreitete Ansicht bei bisherigen Systemen ist, dass sich der Benutzer an ein System eben anpassen muss. Eine solche Anpassung ist aber nicht immer möglich oder praktikabel. Als Beispiel bedenke man gängige Diktiersysteme, bei denen oftmals künstliche Pausen zwischen einzelnen Wörtern notwendig sind. Solche Pausen lassen sich nur schwer angewöhnen und werden auch leicht wieder vergessen sobald sich der Benutzer eigentlich um inhaltliche Dinge Gedanken machen muss.
Die neue Zielsetzung für dieses Gebiet:
- Modellierung der Benutzer- und Modus-zentrierten Sprache mit der ein System umgehen können muss. Welche häufigen Phänomene gibt es in der natürlichen Sprache?
- Entwurf von möglichen Schnittstellen, die sich von den existierenden Restriktionen absetzen.
Daraus folgen natürlich letztlich auch bessere Vermarktungschancen für derartig entwickelte Produkte.
Warum sollte man den Benutzer beachten?
- Kommunikation wird durch das Medium (Sprache, Tastatur, Gestik, etc.) in vielen Punkten beeinflusst.
- Ein gutes System muss Besonderheiten des Mediums beachten. Dies ist mit einem “User-Centered Approach„ gemeint.
Einige Besonderheiten bei gesprochener Sprache
- Alinearer Ablauf (Stottern, Selbstkorrektur)
- Bestätigungsanfragen und Feedback:
- „Sind Sie sicher?“;
- „Jaja, kann ich verstehen“;
- Prosodische und nicht-verbale Modulation der Sprache
- „Ich habe gestern gegessen“. vs. „Ich habe gestern gegessen?“
- Beeinflussung wechselseitiger Kommunikation
- „Wenn ich Sie kurz unterbrechen darf“
- Bewusste Lenkung eines Gespräches mit sprachlichen (und nicht inhaltlichen) Mitteln
Das Problem: Fehltraining gängiger Systeme
Gängige Systeme werden meist basierend auf vorgelesenen Testtexten entwickelt und trainiert, dadurch geht oft der Dialogcharakter der Sprache verloren. Versprecher, Selbstkorrekturen, Zögern und Ähnliches sind eher ungewöhnlich.
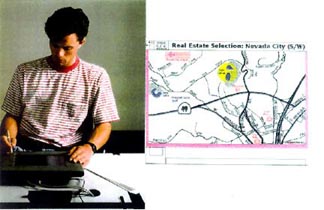
Beispieldialog in multimodalem System
Um kurz zu demonstrieren, wie komplex ein Mensch-Maschine Dialog sein kann, soll hier ein Beispiel eines Systems mit multimodaler Ausgabe aber nur natürlichsprachlicher Ausgabe gezeigt werden:
Benutzer: Wo ist Twin Lakes?
System: [Kartenauschnitt wird angezeigt, ein Punkt wird markiert]
Benutzer: Füge eine Freifläche hinzu.
System: Bitte geben Sie genauere Informationen.
Benutzer: Füge eine Freifläche auf dem nördlichen See ein um Äh... den nördlichen Seeteil der Straße und den Norden mit einzuschließen.
Bestehende Forschungsergebnisse
- Forschung im Auftrag von Telefongesellschaften hat gezeigt, dass es tatsächlich einen großen Bedarf an realistischen Tests gibt.
- Systeme können allein durch die Art und Weise, in der Anfragen an den Benutzer gestellt werden, beeinflussen, in welcher Weise er antworten wird, z.B. durch die offende Unterstützung besonders kurzer Antworten.
- Alleine durch Änderungen an Oberfläche und Präsentation machen Benutzer zwischen zwei- und achtmal so selten bestimmte Arten von Fehlern.
- Oft geht dies nicht einmal auf Kosten der Akzeptanz des Systems, manches wird sogar vom Benutzer als Verbesserung empfunden.
Ziele der Studien dieser Arbeit:
- Quellen von Variabilität indentifizieren (Variabilität: Benutzer sagen in genau der selben Situation unterschiedliche Dinge)
- Modellierung dieser Variabilitäten unter Berücksichtigung des technisch machbaren
- Erforschung von Systemdesigns, die bestimmte Quellen von Variabilität reduzieren
Wenn diese Ziele erreicht werden, so lassen sich daraus robustere Systeme basierend auf möglichst unveränderten Sprachmustern konstruieren. Der Benutzer muss sich diesen Systemen wesentlichen weniger anpassen, als dies bislang der Fall ist.
Die richtige Testumgebung
Da es darum geht, Funktionen noch nicht fertig gestellter Systeme zu untersuchen, müssen eben diese Systeme simuliert werden, dies geschieht über sog. Wizard of Oz-Experimente. Dafür sprechen auch noch weitere Gründe:
- Simulation ist billiger und schneller als Entwicklung und mehrfache Abänderung eines tatsächlichen Prototypen
- Unbeschränktere Möglichkeiten
- Erkannte Probleme können leichter isoliert werden
Untersuchtes Phänomen: Unflüssige Sprechweise (Disfluencies)
Beispiele:
- Selbstkorrektur: „Westlich von, nein, östlich von hier.“
- Fehlstarts: „Ich will... wo ist hier ein Krankenhaus?“
- Spontane Wiederholungen: „Ich fahre nach Hinter... Hintertupfingen“
- Füllsel: „Ich, ähm, naja, weiß nicht so recht.“
Ist die automatische Korrektur von Unflüssigkeiten möglich?
- Unflüssigkeiten sind anerkanntermaßen eine schwere Hürde für robuste sprachgesteuerte Systeme.
- Es wird nach verlässlichen Methoden gesucht, Unflüssigkeiten anhand von akustischen, prosodischen, syntaktischen oder semantischen Mustern zu erkennen.
- Dies scheint mittelfristig vielversprechend zu sein, doch gibt es bislang noch keine brauchbaren Ergebnisse aus dieser Richtung, daher sollen in dieser Arbeit andere Möglichkeiten aufgezeigt werden.
Wann treten Unflüssigkeiten auf?
Die Tabelle zeigt, dass sich in Abhängigkeit von der Dialogsituation die Häufigkeit von Unflüssigkeiten bis zu einem Faktor von elf ändert.
Unflüssigkeiten pro 100 Worte:
Mensch-Mensch Dialog: 2-Personen Telefonat 8,83 3-Personen Telefonat 6,25 2-Personen Gespräch 5,50 Monolog 3,60 Mensch-Maschine Dialog: Unbeschränkter Dialog 1,74 - 2,14 Strukturierter Dialog 0,78 - 1,70
Interface Design als Ausweg?
Hypothese: Durch geschicktes Interface Design lassen sich Mensch-Maschine Dialoge so strukturieren, dass Unflüssigkeiten minimiert werden.
Dazu sind aber zunächst empirische Studien und eine quantitative Modellierung der festgestellten Phänomene notwendig, um festzustellen, welche Phänomene in der Praxis mit welcher Relevanz auftreten.
Lange Sätze = Fehler?
- Komplizierte, und somit lange Satzkonstruktionen sind fehleranfällig.
- 80% aller Unflüssigkeiten lassen sich allein anhand der Textlänge erkennen!
- Sätze mit 1 - 6 Worten: 0,66 Fehler
- Sätze mit 7 - 18 Worten: 2,81 Fehler
Unflüssigkeiten vermeiden durch Förderung kurzer Sätze
- Möglichkeit, lange Antworten zu geben:
- „Wo möchten Sie, dass das Auto abgeholt werden soll?“
- Unterschwellige Aufforderung zu einer knappen Antwort:
- „Ort, an dem das Auto abgeholt werden soll:“
- Reduktion der Fehler um 30 - 40%!
Anwendungsgebiete:
- Sprachliche Eingaben (wie gesehen)
- Numerische Eingaben, z.B. bei der Interaktion mit einem Telefonbanking-System
- Kartenbasierte Eingaben, z.B. bei geografischen Informationssystemen
Nebeneffekte:
- Geschwindigkeitssteigerung
- Höhere Benutzerakzeptanz: In Tests zogen zwei von drei Probanden die kurze Version vor.
- Komplexität der Sätze nimmt stark ab, einfachere Spracherkenner sind möglich.
Gibt es Abhängigkeiten der Fehlerrate vom Inhalt?
Ortsbeschreibungen bergen eine etwa 50% höhere Chance für Unflüssigkeiten, Selbst relativ einfache Ortsbeschreibungen verführen zu Fehlern.
Beispiele hierfür ist das Verwechseln von rechts und links, Fehler bei der Zuordnung von Himmelsrichtungen und unklare Referenzen auf andere Objekte oder Orte.
Lösung für Ortsbeschreibungen
- Multimodale Eingabe erscheint sinnvoll.
- Möglicherweise optimal: Grafisches Display mit der Möglichkeit, mit einem Stift auf Orte zu tippen.
- Mit einem Stift auf Punkte zu tippen ist eine sehr natürliche Handlungsweise.
- Hohe Akzeptanz, 95% der Probanden nutzten die Möglichkeiten der direkten Anwahl eines Ortes per Stift.
Untersuchtes Phänomen: Hyperartikulation
Hyperartikulation umfasst:
- Überbetonung
- Unnötig langsame Sprechweise
- Unnatürlich deutliche Sprechweise
- Andere Wortwahl
Gründe von Hyperartikulation
Hyperartikulation ist zumeist der Versuch des Benutzers, betont deutlich zu sprechen, um dem System die Spracherkennung zu erleichtern. Sie tritt meist auf, nachdem das System signalisiert hat, dass es eine Eingabe nicht verstanden hat.
Probleme durch Hyperartikulation?
- Sprachverstehenede Systeme (NLIs) werden meist anhand von fehlerfreien Testsätzen trainiert, die Erkennung von Hyperartikulation gehört nicht zum üblichen Training.
- Während HA im Mensch-Mensch Dialog das Verständnis vereinfacht, erschwert es einem NLI-System die Arbeit zusätzlich!
>> Produktion weiterer Fehler, Frustrationsgefahr! Diese Frustrationsgefahr ist auch bekannt als "Spiral Errors", d.h. ein Fehler des Systems sorgt dafür, dass in der Folge mit hoher Wahrscheinlichkeit weitere Folgefehler auftreten, die ihrerseits wieder Folgefehler verursachen und so weiter. In der Praxis führt dies oft dazu, dass ein Benutzer die Arbeit abbricht und das System nicht mehr verwendet.
Analyse von Hyperartikulation
- Definitionen für Stärke und Art der Änderungen bei HA
- Modellierung verschiedener Phänomene, Klassifizierung nach der Art vorgenommener Änderungen
- Übertragung auf Vorschläge zur Verbesserung von Spracherkennern
Beobachtete Phänomene
- Vergleich vor/nach einem Fehler:
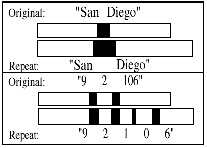
- 12% längere Segmente (Sätze)
- 73% längere Gesamtdauer der Pausen
- 91% mehr Pausen
- Entspannte, umgangssprachliche Ausdrucksweise wird durch klare Aussprache abgelöst (alle Beispiele aus dem Amerikanischen):
- 't' statt 'd': "Forty" statt "Fordy"
- 'nt' statt 'nn': "Twenty" statt "Twenny"
- Ausgelassene Silben: "Eleven" statt " 'leven" >
Lösungsansätze
- Training der Spracherkenner auch mit Hilfe von hyperartikuliertem Text.
- Entwurf mehrerer Spracherkenner, die je nach erkannter Situation zugeschaltet werden können. Es wäre denkbar, spezielle Hyperartikulationserkenner zu bauen. Abhängig vom System kann es manchmal sehr leicht sein, zu erkennen, welcher Erkenner jetzt gerade benutzt werden muss. Man denke an ein Formulargesteuertes Programm, dass bei einer nicht erkannten Eingabe die selbe Eingabestelle ein zweites Mal benutzen muss; in so einer Situation wäre es ein Leichtes, auf den HA-Erkenner umzuschalten.
- Vermeidung von HA durch multimodale Eingabemöglichkeiten. Wenn man manche Dinge schlecht erklären kann, kann man sie vielleicht leichter zeigen.
Multimodale Eingaben
- Es ist sehr natürlich, nach einer fehlgeschlagenen Eingabe das Medium zu wechseln (dreimal mehr als sonst).
- Benutzer erfassen selbst sehr gut, welche Eingabemethode am einfachsten ist.
- Chancen für Folgefehlern werden aufgrund stark unterschiedlicher Systeme minimiert.
Erfahrungen mit multimodaler Eingabe
- Benutzer verwenden Sprache, um Objekte zu benennen oder Objekte anzufordern, die gerade nicht sichtbar sind.
- Benutzer verwenden Zeigegestik um Orte zu markieren, (unregelmäßige) Linien zu ziehen und Regionen zu markieren.
Beispiel für Vorteile (Militärisch-geografisches System)
Man stelle sich ein miltitärisches System vor, dass mit exakten Koordinaten arbeiten muss:
- Monomodal:
- „Setze einen Punkt auf 1 5 2 0 3 4 und nenne ihn Objekt Alpha.
Zurück.
Setze Objekt Alpha auf 1 5 1 0 3 6.
Zurück.
Setze Objekt Alpha auf 1 5 1 0 3 7.“ - Multimodal:
- „Objekt Alpha [klick]“
Zusammenfassung
- Sprachverstehende Systeme müssen unter realistischen Bedingungen entwickelt und getestet werden.
- Modellierung von Fehlerquellen ist hilfreich.
- Multimodale Eingaben sind oft erstrebenswert.
Weitere Resourcen:
- Die Vortragsfolien als PowerPoint-Präsentation sind auf Anfrage verfügbar